…for software engineers.
Numerous books have been written about user experience design, and at least some of them are well worth reading. But this presupposes that UX design requires a certain kind of unique expertise, and that its application must be left to the experts. My goal for today is to convince you that, like any other field, the basics are fairly easy to grasp, and as a software engineer, it would be remiss of you to not learn and apply it in the products that you build.
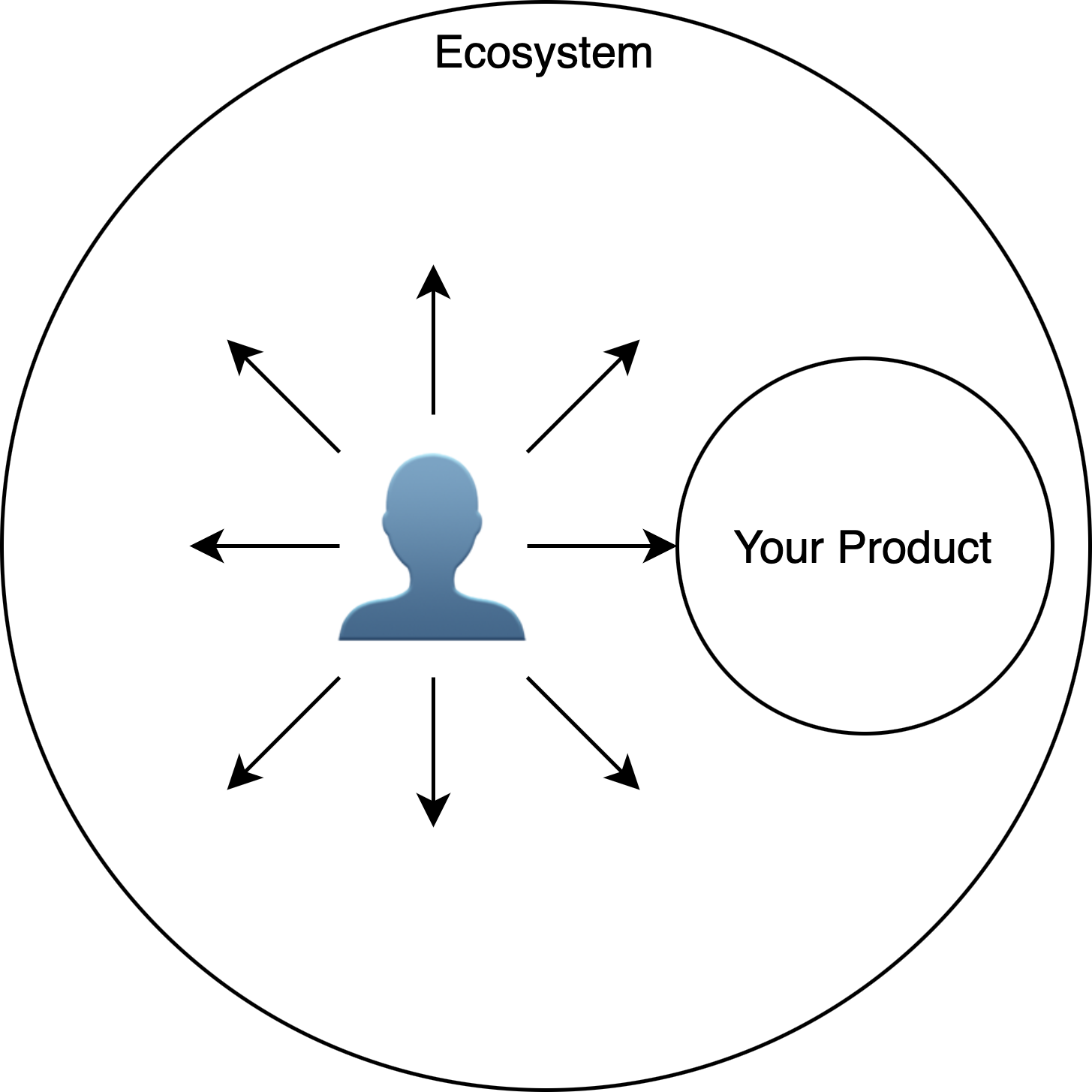
The term “User Experience” (UX) is broader than, and in a sense distinct from the term “user interface”, and isn’t limited to graphical screens or visual elements. User experience is truly about the experience of the user, and captures the qualitative aspect of their interactions with their ecosystem in the context of your product. Notice how I said “interactions with their ecosystem” rather than “interactions with your product” – making the right UX decisions requires a good understanding of the user’s ecosystem, and the role your product plays within that ecosystem.
Without further ado, here are some critical points to remember:
User-centric. First and foremost, remember that any good UX begins by viewing the world from the perspective of the user, not the perspective of the product or its technical implementation. If I am the user, what goal am I trying to accomplish? How is the product making my life easier? Taking this user-centric approach is surprisingly hard, especially for someone who’s deeply steeped in building their own product. You might need to unlearn and forget what your product does for a while, and re-examine the problem afresh.
Goal-oriented. In user-centric design, any activity taken up by the user can be attributed to a goal that they have in mind. Users don’t mindlessly click buttons; they do so because they believe it helps them achieve their goal. What is that goal? How can it be expressed clearly in the language of the user? Notice that any goal expressed in this manner is effectively agnostic to your product. For instance, the user does not want to “create an order for pencils, enter their payment information, check out, and confirm the order”; rather, she just wants to buy pencils.
The role of your product in this context is two-fold. First, it is to convey to the user that taking a specific action clearly helps them make progress towards achieving their goal. Second, when simple actions don’t suffice, it is to help break down the goal into smaller sub-goals, and guide the user towards understanding how fulfilling these sub-goals would, in fact, help them achieve their overarching goal.
In most cases, helping the user achieve their goal in the quickest and simplest possible way means fewer buttons, prompts, steps, or visual elements. However, there are notable exceptions, driven by concurrent goals that subtly conflict with or constrain each other. For instance, although Amazon’s “1-Click” experience eliminates all steps other than a single click, users actually prefer the “Buy Now” experience that requires two clicks, first to click the “Buy Now” button, and second to confirm the order after checking their payment and delivery details. The reason for this is quite simple: users have the additional goals of wanting to use the right credit card for their order, and wanting to have the item delivered to the right address. In the “Buy Now” experience, they can view these details prior to confirming their order, whereas the “1-Click” experience, though arguably faster, leaves these auxiliary goals unmet.
Reward-driven. As should be evident by now, the user is not a mindless automaton, but rather a reward-driven agent. Users like to be rewarded for the actions they take, and shy away from actions that are repetitive or ambiguous with regard to whether they lead towards their goal. By being thoughtful about each action requested and ensuring that any action results in the completion of a sub-goal, your product can make every step rewarding and valuable to the user, leading to a delightful experience.
Late binding to product concepts. A common pitfall especially amongst software engineers is that they identify closely with the product that they are creating, and consequently (and unknowingly) force their users to learn about and understand concepts that are bespoke to the product. These concepts may include product names, feature branding, and implementation-specific entities. Sometimes, the introduction of new concepts is unavoidable (e.g., “to buy pencils, you must <place> an <order> for a <quantity> of <items> listed as ‘pencils'”). Applying the idea of being reward-driven (from the previous section), it is best not to introduce new concepts unnecessarily and require users to learn what they mean, and if you absolutely must, look for the “last responsible moment” to do so.
Integrated with the ecosystem. All products have a need for some degree of integration with the user’s ecosystem. Remember that the user’s goals are agnostic to your product and span their ecosystem (including products you don’t own and constraints you don’t control). For instance, if your product offers data entry features that eliminates the need for standalone Excel spreadsheets in that context, is there a different reason (unrelated to your product) that the user still needs to avail of those Excel spreadsheets? If the answer is yes, you might be doubling the amount of data entry from the perspective of the user! And if so, the ability to export your data to Excel may become a life-saving feature in that ecosystem. In general, consider how your product seeks to change the user’s ecosystem, and whether that change is an overall improvement or worsening of the user experience.
In conclusion, I would say that a good UX is like candles on a birthday cake: of course, you absolutely need the cake (your product innovations and its unique value proposition to the user), but you don’t want to proceed to cut the cake without lighting candles on it first. Also, you don’t need to be afraid of improvising, if you’ve forget to buy the candles from the store.
All you have to do is put yourself in the shoes of your users.
That’s all for today, folks! 🖖